Momentum, Not Autopilot: Why Agentic RE Beats AI Complacency
The powerful AI made it likelier that the consultants "fell asleep at the wheel" and made big errors when it counted. -- Ethan Mollick, Co-Intelligence

Ethan Mollick has a warning for anyone using AI: the better it gets, the easier it is to stop paying attention. When outputs are polished and instant, you stop thinking critically. You stop building skill. You become a passenger.
He's right, but only if you're using AI wrong.
The Complacency Trap
Mollick's research found that using high-quality AI actually made people lazier, more careless, and less skilled in their own judgment. His concern maps cleanly onto security research. Picture a reverse engineer who pastes decompiled code into ChatGPT and accepts whatever summary comes back. No validation. No tracing of control flow. No understanding of why the vulnerability exists, just a plausible-sounding explanation they can drop into a report.
That's the complacency trap. In vulnerability research, complacency doesn't just mean weaker work. It means missed bugs, wrong conclusions, and false confidence in systems that protect real infrastructure.
Momentum Over Autopilot
There's another way to use AI, one that makes you more engaged, not less.
In a recent post, How LLMs Feed Your RE Habit: Following the Use-After-Free Trail in CLFS, we showed what this looks like in practice. Using a local LLM connected to Ghidra through pyghidra-mcp, we traced a use-after-free vulnerability (CVE-2025-29824) in Windows' Common Log File System driver.
The LLM didn't do the thinking. It handled the friction: scanning binaries for FsContext2 references, decompiling candidate functions, mapping IOCTL dispatch paths.
The analyst stayed focused on the actual investigation, understanding the race condition between IRP_MJ_CLEANUP and IRP_MJ_DEVICE_IO_CONTROL, and validating the vulnerability surface against the real binary.
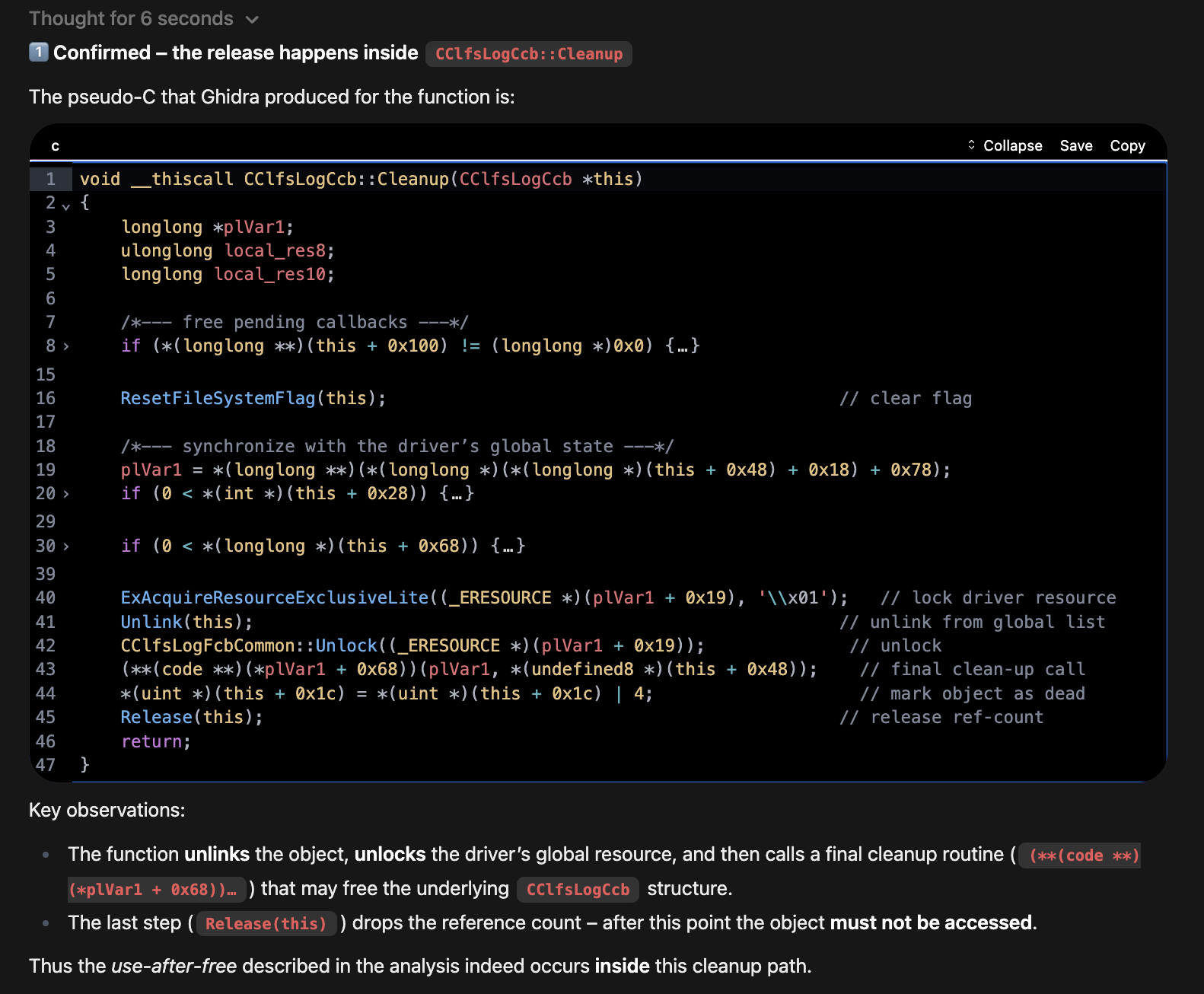
The LLM independently surfaced the same vulnerable functions identified in StarLabs' manual analysis. Not by guessing, but through actual binary analysis driven by tool calls. The analyst verified every finding in Ghidra.
That's not autopilot. That's momentum. The thing that keeps you moving when the system gets complicated, when cross-referencing gets tedious, when you'd otherwise lose your thread in a sea of decompiled output.
The Difference Is Skill
Mollick's warning still applies here: momentum without expertise is just speed without direction.
Someone with no RE background who tried to replicate this workflow might accept the LLM's output table at face value without knowing how to verify it. They'd have velocity but no judgment. That's the "asleep at the wheel" failure mode Mollick describes.
The answer isn't avoiding AI. It's knowing enough to use it as leverage instead of a crutch. You need to know what questions to ask, how to spot when the LLM is wrong, and when to override it. That comes from hands-on work with the systems you're analyzing, not from watching an LLM do it for you.
Building the Skill to Stay Awake
This is the core philosophy behind Agentic RE: Automating Reverse Engineering & Vulnerability Research with AI. The course isn't about handing your analysis to an LLM. It's about learning to direct AI as an extension of your own reasoning:
- Connecting RE tools to LLMs through MCP so the AI operates on real binary data, not guesses
- Building custom MCP servers that give LLMs structured access to your analysis environment
- Designing agentic workflows where you set the investigation strategy and the AI handles execution
- Running local models so sensitive analysis stays private and reproducible
- Validating everything, because in this field, output you didn't verify is worse than no output at all
The CLFS walkthrough is a preview of what this looks like when the pieces come together. A 2-3 hour manual analysis compressed to around 20 minutes, with higher confidence, because the analyst spent their time reasoning about the vulnerability instead of grinding through cross-references.
Don't Fall Asleep. Build Leverage.
Mollick is right that AI can make you passive. But that's a choice. The people who get the most out of these tools won't be the ones who accept outputs uncritically. They'll be the ones who know their domain well enough to stay engaged, stay critical, and keep their hands on the wheel.
LLMs don't replace the work. They feed the habit. But only if you have the skills to direct them.
Want to build these skills? Subscribe to our newsletter for course announcements, or check out the full course catalog.